

GPT 5.6 明天要来了
从海外内测的风评来看,GPT5.6 是 GPT 5.5 的全面升级版本,价格也一样,预计会是个很成功的模型
但是,大多数内测者都说 GPT5.6和 Fable 这种质变的感觉不太一样,在各方面都会差一点点
2倍高价的 Fable 依然是智能的巅峰
by @AGENT橘 #AI探索站
从海外内测的风评来看,GPT5.6 是 GPT 5.5 的全面升级版本,价格也一样,预计会是个很成功的模型
但是,大多数内测者都说 GPT5.6和 Fable 这种质变的感觉不太一样,在各方面都会差一点点
2倍高价的 Fable 依然是智能的巅峰
by @AGENT橘 #AI探索站
我和女朋友异地,每天晚上用飞书会议聊天。飞书有文字纪要,所以我攒下了五六百篇我们的聊天。
我让 Claude Code 基于这些纪要去理解女朋友的偏好,帮我推荐礼物,推荐得特别好。大节日礼物、每次从北京出差带回去的几十块小礼物,它推荐的都特别准。比如女朋友喜欢甜酷风的东西,我自己都不知道——但她说过,她说过但是我没记下来,AI 能抽出来。她说过她的 AppleWatch 表带发黄了,她真的说过这句话,我也记得,但我想不到要再买个新表带,AI 就知道。
她觉得脸上有些痘印,皮肤变得暗沉发黄,很苦恼,Claude Code 推荐了美容仪。我同时用了 ChatGPT、Claude、Gemini的 deep research,也用了 Claude Code去调研具体买哪款美容仪。Claude Code 效果比其他的都好——要知道,Claude Code 是没有专门为 Deep Research 适配过的(至少我当时还没有体验到),它只是简单地做一轮又一轮的搜索,但它只要有了上下文,哪怕只是做简单的的搜索,都比专门做深度搜索的工具更好,因为上下文能带来更精准的判断。它知道我女朋友脸部的各种细节描述,知道我女朋友的各种购物偏好。所以能推出更精准的美容仪。那些专门做深度搜索的工具就很差,因为它只有我说的那几百字。
大模型是预测。当你的上下文不充分,它的预测就是给你一个最平均的回答,也许这个平均的回答已经很好了。但当你给它的上下文足够充分,你会对它施加一个强大的引力和扭转,它会给你一个更好的回答——也许这个回答在大众的意义上并不是最好的,但它对你就是最好的。
by @许涵之 #AI探索站
我让 Claude Code 基于这些纪要去理解女朋友的偏好,帮我推荐礼物,推荐得特别好。大节日礼物、每次从北京出差带回去的几十块小礼物,它推荐的都特别准。比如女朋友喜欢甜酷风的东西,我自己都不知道——但她说过,她说过但是我没记下来,AI 能抽出来。她说过她的 AppleWatch 表带发黄了,她真的说过这句话,我也记得,但我想不到要再买个新表带,AI 就知道。
她觉得脸上有些痘印,皮肤变得暗沉发黄,很苦恼,Claude Code 推荐了美容仪。我同时用了 ChatGPT、Claude、Gemini的 deep research,也用了 Claude Code去调研具体买哪款美容仪。Claude Code 效果比其他的都好——要知道,Claude Code 是没有专门为 Deep Research 适配过的(至少我当时还没有体验到),它只是简单地做一轮又一轮的搜索,但它只要有了上下文,哪怕只是做简单的的搜索,都比专门做深度搜索的工具更好,因为上下文能带来更精准的判断。它知道我女朋友脸部的各种细节描述,知道我女朋友的各种购物偏好。所以能推出更精准的美容仪。那些专门做深度搜索的工具就很差,因为它只有我说的那几百字。
大模型是预测。当你的上下文不充分,它的预测就是给你一个最平均的回答,也许这个平均的回答已经很好了。但当你给它的上下文足够充分,你会对它施加一个强大的引力和扭转,它会给你一个更好的回答——也许这个回答在大众的意义上并不是最好的,但它对你就是最好的。
by @许涵之 #AI探索站
还没等我出手,Kimi已经公开预测了这届世界杯的冠军,太不像话了。
在动用包含300个子Agent的集群,从战术、球员、伤病、赛程、历史、舆情、天气、心理、赔率变动、专家观点全都跑了一遍之后,Kimi预测可能要夺冠的是:
德国。
行吧,聊这个我可真不困了,作为一个战绩可查的资深⋯⋯中国体彩消费者,我对Kimi敢于立Flag的勇气,是深感尊重的。
要知道,从盘口来看,德国的赔率(9.5)并不低,在所有球队里排在第7位,所以Kimi并没有按照最大概率——也就是最稳妥的方案——去做判断,是真有自己的想法的。
当然,即便是选夺冠热门法国、西班牙,赔率(4.5)的风险仍然很高,说白了,早在开幕前就暴论最后的冠军,本身就是一件吃力不讨好的事情。
所以我才要狠夸Kimi的「敞亮」,不光是冠军,Kimi还要对全部104场比赛全都做出公开预测,包括赛后核验以及复盘,一场不落。
这就更硬核了,完全不怕打脸呐⋯⋯(注意,该预测非投注建议、非投资建议、非收益承诺。)
严格来说,Kimi并没有笃信德国是最有希望夺得这届世界杯的参赛队伍,而是认为德国的市场定价在强队里过于低了。
在使用了8种数学模型——包括SLO评级、Sixon-Coles泊松、XGBoost机器学习、Opta蒙特卡洛模拟等等——对48支球队逐一分析之后,Kimi得出了这么一个结论:
德国的模型预测概率,和市场赔率存在最高的偏差值,达到+3.6pp。
什么意思呢?
就是在判断德国是否有机会捧起大力神杯这件事情上,模型比市场多预测了3.6个百分点,所以认定德国,在理性上是回报确定性最高的选择。
就很像量化投资的策略,一家公司好不好并不重要,重要的是它有没有被市场正确定价,一家被高估的好公司,和一家被低估的差公司,显然后者更有买入潜力。
不同的是,量化机构需要雇佣一大票分析师,以及重金采购商业软件,而Kimi靠着几百个Agent昼夜不息的连轴转,自个儿就把整个项目给做完了。
BTW,搞价值投资的巴菲特最讨厌量化了,还贡献过「Beware of geeks bearing formulas」的金句,哈哈哈⋯⋯
我很推荐大家去看一下Kimi同时发布的预测报告,完整版PDF超过200页,量大管饱,如果看不下去,扔给Kimi让它帮你总结也行,递归循环了有没有?
另外就是,应该也不需要我特别说明吧,Kimi这么兴师动众的「Predict In Public」,并非是为了真的去当那个洞悉神谕的预言家,作为一家注重审美和趣味大模型厂商,它是在用一种奇观的形式,向世界演示AI的能力边界和局限性。
世界是可被编码的,这是AI得以成立的底层逻辑。
无论是图灵坚信思考是一个工程问题、而非哲学家心中的灵魂之类,还是香农在上世纪五十年代就用人类受试者去玩猜字游戏、用以论证智能始于对信息的预测,所有的历史研究和前沿走向都并轨于同一个共识:
凡事皆可压缩。
当人类知识的总和被压缩到了极致,就能制造一个通晓万物的机器出来,它能通过模拟已经存在过的和还没有发生的所有过程,去得到每一项任务的最优解。
这听起来很科幻,也足以引起事关自由意志的思辨,但我们正确切的走在这条路上,大模型的运行原理就是预测下一个词元,这是众所周知的,香农的遗憾在于他买不到英伟达的GPU。
所以能够理解Kimi为什么要预测世界杯了么?
面对这种长链路、随机性、没有标准答案的复杂目标,如果AI也能完成媲美甚至优于人类表现的任务,那么它在通用性层面的可用,就不再存疑了。
2010年的世界杯,数以亿计的人类在围观一条名叫保罗的章鱼,用它黏糊糊的触手从闭合的箱子里选择比赛赢家。
16年后,开箱的角色变成了连生物都算不上的AI,从克苏鲁的古神符号,到后现代的赛博朋克,如此交替,本身就充满了隐喻。
隐喻那种不可言说的混沌,让渡给了可被测量的科技。
这让我想起在自己投入了无数个通宵的游戏「文明6」里,解锁信息时代的科技之后,会出现在屏幕上的那句台词:
「现在天上有31颗卫星在地球上空环绕,不为别的,就为了告诉你便利店怎么走。」
取之于硅,用之于碳,这才是AI正确的打开方式,对不对?
by @阑夕ོ #AI探索站
在动用包含300个子Agent的集群,从战术、球员、伤病、赛程、历史、舆情、天气、心理、赔率变动、专家观点全都跑了一遍之后,Kimi预测可能要夺冠的是:
德国。
行吧,聊这个我可真不困了,作为一个战绩可查的资深⋯⋯中国体彩消费者,我对Kimi敢于立Flag的勇气,是深感尊重的。
要知道,从盘口来看,德国的赔率(9.5)并不低,在所有球队里排在第7位,所以Kimi并没有按照最大概率——也就是最稳妥的方案——去做判断,是真有自己的想法的。
当然,即便是选夺冠热门法国、西班牙,赔率(4.5)的风险仍然很高,说白了,早在开幕前就暴论最后的冠军,本身就是一件吃力不讨好的事情。
所以我才要狠夸Kimi的「敞亮」,不光是冠军,Kimi还要对全部104场比赛全都做出公开预测,包括赛后核验以及复盘,一场不落。
这就更硬核了,完全不怕打脸呐⋯⋯(注意,该预测非投注建议、非投资建议、非收益承诺。)
严格来说,Kimi并没有笃信德国是最有希望夺得这届世界杯的参赛队伍,而是认为德国的市场定价在强队里过于低了。
在使用了8种数学模型——包括SLO评级、Sixon-Coles泊松、XGBoost机器学习、Opta蒙特卡洛模拟等等——对48支球队逐一分析之后,Kimi得出了这么一个结论:
德国的模型预测概率,和市场赔率存在最高的偏差值,达到+3.6pp。
什么意思呢?
就是在判断德国是否有机会捧起大力神杯这件事情上,模型比市场多预测了3.6个百分点,所以认定德国,在理性上是回报确定性最高的选择。
就很像量化投资的策略,一家公司好不好并不重要,重要的是它有没有被市场正确定价,一家被高估的好公司,和一家被低估的差公司,显然后者更有买入潜力。
不同的是,量化机构需要雇佣一大票分析师,以及重金采购商业软件,而Kimi靠着几百个Agent昼夜不息的连轴转,自个儿就把整个项目给做完了。
BTW,搞价值投资的巴菲特最讨厌量化了,还贡献过「Beware of geeks bearing formulas」的金句,哈哈哈⋯⋯
我很推荐大家去看一下Kimi同时发布的预测报告,完整版PDF超过200页,量大管饱,如果看不下去,扔给Kimi让它帮你总结也行,递归循环了有没有?
另外就是,应该也不需要我特别说明吧,Kimi这么兴师动众的「Predict In Public」,并非是为了真的去当那个洞悉神谕的预言家,作为一家注重审美和趣味大模型厂商,它是在用一种奇观的形式,向世界演示AI的能力边界和局限性。
世界是可被编码的,这是AI得以成立的底层逻辑。
无论是图灵坚信思考是一个工程问题、而非哲学家心中的灵魂之类,还是香农在上世纪五十年代就用人类受试者去玩猜字游戏、用以论证智能始于对信息的预测,所有的历史研究和前沿走向都并轨于同一个共识:
凡事皆可压缩。
当人类知识的总和被压缩到了极致,就能制造一个通晓万物的机器出来,它能通过模拟已经存在过的和还没有发生的所有过程,去得到每一项任务的最优解。
这听起来很科幻,也足以引起事关自由意志的思辨,但我们正确切的走在这条路上,大模型的运行原理就是预测下一个词元,这是众所周知的,香农的遗憾在于他买不到英伟达的GPU。
所以能够理解Kimi为什么要预测世界杯了么?
面对这种长链路、随机性、没有标准答案的复杂目标,如果AI也能完成媲美甚至优于人类表现的任务,那么它在通用性层面的可用,就不再存疑了。
2010年的世界杯,数以亿计的人类在围观一条名叫保罗的章鱼,用它黏糊糊的触手从闭合的箱子里选择比赛赢家。
16年后,开箱的角色变成了连生物都算不上的AI,从克苏鲁的古神符号,到后现代的赛博朋克,如此交替,本身就充满了隐喻。
隐喻那种不可言说的混沌,让渡给了可被测量的科技。
这让我想起在自己投入了无数个通宵的游戏「文明6」里,解锁信息时代的科技之后,会出现在屏幕上的那句台词:
「现在天上有31颗卫星在地球上空环绕,不为别的,就为了告诉你便利店怎么走。」
取之于硅,用之于碳,这才是AI正确的打开方式,对不对?
by @阑夕ོ #AI探索站
最近半年疯狂在用Codex,整理一下目前我最常用的10个日常场景。
1、产品需求池自动管理
开发赚钱的虚拟产品,首先是对核心需求的掌握。所以,我把用户反馈、评论区、私聊记录、差评、退款理由、同行产品页都丢进去,让 Codex 自动整理,甚至专门做了一个skill,判断:
解决的到底是用户什么痛点
交付轻,售后压力低,
尽量自动化
需求长期存在,
不过度依赖单一平台
用户容易理解,没有太多心智成本
竞争不激烈,没几个同行做
让Codex 帮你判断需求质量。现在最重要的能力不是“开发能力”,而是需求筛选能力
代码可以让AI写,但需求判断错了,写得越快,亏得越多。
2、自动做竞品拆解
除了从需求分析,还会让Codex做同行竞品的拆解。这件事很重要。
有很多产品,看起来销量不错,但一拆就发现,交付很重,售后很多,并不适合我这种想做轻交付、可自动化、一人公司模式的人。
所以我现在看竞品,不是为了抄。而是为了看清楚谁在卖,卖给谁,卖什么,怎么交付,利润空间在哪里,风险在哪里,还有没有没被满足的小需求,我去做,有什么独特的优势。
谋定而后动。
3、开发赚钱产品
前面讲的是需求判断,需求判断完之后,下一步就是把它开发成真正能卖钱的产品。这一点本来就是 Codex 最基础的事情:写代码。
以前做一个产品,很容易从零开始想。现在不是,现在是套流程,先判断需求,再拆核心功能,再确定页面和交付链路,再决定后端和数据库,最后部署上线,根据用户反馈继续迭代。这样一来,开发速度就非常快。
很多虚拟产品,本质上底层技术结构都很像,只是换了不同用户、场景和内容一旦模板跑通,后面就不那么吃力,而是复制、改造、组合、上线。
这也是我现在接定制项目的底气。因为客户要的东西,就是把一个需求变成能用、能交付、能上线、能收钱的产品。Codex 负责提高开发效率,而我负责判断需求、设计产品结构、把控交付边界、控制成本和风险。
所以我现在对 AI 编程最大的感受是,它不是让我变成一个传统程序员,而是让我有能力把一个赚钱想法,更快变成一个可交付的产品。
做得越多,积累越多,开发越快,我就越能抓住市场里的小机会。这才是 Codex 对我真正的价值。
4、自动整理卖点+作产品海报
产品做出来之后,下一步不是急着发售,而是先把卖点讲清楚。很多产品不是没价值,而是用户看不懂。你自己知道功能很多、很有用,但用户只关心一件事:这个东西到底能不能帮我解决问题?
所以我会把产品功能、用户痛点、竞品页面、用户反馈、聊天记录丢给 Codex,让它先帮我整理:这个产品适合谁,解决什么问题,能节省什么时间,能减少什么麻烦,为什么值得买,买完之后能拿到什么。
这些问题整理清楚之后,再让 Codex 基于卖点生成对应的商品海报。
产品做出来只是第一步。能不能把价值讲清楚,才是真正进入销售阶段。
5、搭建产品文档和交付说明
虚拟产品最怕一件事:东西做出来了,但用户不知道怎么用。
所以我会让Codex 帮我把产品自动整理成,使用教程说明书。
这样可以减少大量重复沟通。
6、用 flomo MCP 搜索素材写稿
写文章时,我会直接让 Codex 从 flomo 里搜索相关素材。
以前写一篇文章,要自己翻笔记、找案例、回忆之前讲过什么。
现在可以直接让它把相关笔记都捞出来,再按主题、观点、案例、金句整理。
这对我这种长期写作的人很有用。
因为真正有价值的内容,不是临时编出来的。
而是过去长期观察、思考、实践之后,被重新组织出来的。
7、用飞书CLI存稿入库
写好的稿件,我会通过飞书 CLI 直接存入飞书知识库。
不用再手动复制、粘贴、改格式、建文件。这类动作单次看起来不大,但每天重复,非常消耗人。
Codex 最适合干重复、琐碎、低创造力,但又必须做对。能自动化的,就不要用自己的注意力去换。
8、建立内容创作系统日报
我用 Codex 设置了一个内容创作系统轻量日报。
每天自动帮我回顾,哪些选题可以推进?哪些素材值得捞出来?哪些草稿需要继续处理?哪些文章可以改成视频?哪些内容可以导向产品?哪些旧内容可以重新分发?
这个东西特别适合自媒体人。
因为自媒体最大的内耗之一,就是每天都觉得自己要重新开始。
但其实你过去积累过很多东西。只是需要一个系统每天帮你捞起来。
9、自动做小红书封面
现在做小红书封面,我基本也会交给 Codex。
主要有两种方式:一种是看到不错的同行封面,就把图片丢进去,让 Codex 做多模态分析,拆出它的标题、排版、颜色、结构和视觉重点,然后在这个基础上稍微改一版,变成适合自己产品的封面。
另一种就是直接把产品卖点和笔记主题给 Codex,让它生成几版不同风格的封面图,不断测试哪种点击更好。封面这件事以前很耗时间,现在基本就是丢进去、分析、改图、测试。
稿定会员我都不充了。
10、其他零碎的杂活,我也是能用就用Codex,会有意外的惊喜
by @辉老板 #AI探索站
1、产品需求池自动管理
开发赚钱的虚拟产品,首先是对核心需求的掌握。所以,我把用户反馈、评论区、私聊记录、差评、退款理由、同行产品页都丢进去,让 Codex 自动整理,甚至专门做了一个skill,判断:
解决的到底是用户什么痛点
交付轻,售后压力低,
尽量自动化
需求长期存在,
不过度依赖单一平台
用户容易理解,没有太多心智成本
竞争不激烈,没几个同行做
让Codex 帮你判断需求质量。现在最重要的能力不是“开发能力”,而是需求筛选能力
代码可以让AI写,但需求判断错了,写得越快,亏得越多。
2、自动做竞品拆解
除了从需求分析,还会让Codex做同行竞品的拆解。这件事很重要。
有很多产品,看起来销量不错,但一拆就发现,交付很重,售后很多,并不适合我这种想做轻交付、可自动化、一人公司模式的人。
所以我现在看竞品,不是为了抄。而是为了看清楚谁在卖,卖给谁,卖什么,怎么交付,利润空间在哪里,风险在哪里,还有没有没被满足的小需求,我去做,有什么独特的优势。
谋定而后动。
3、开发赚钱产品
前面讲的是需求判断,需求判断完之后,下一步就是把它开发成真正能卖钱的产品。这一点本来就是 Codex 最基础的事情:写代码。
以前做一个产品,很容易从零开始想。现在不是,现在是套流程,先判断需求,再拆核心功能,再确定页面和交付链路,再决定后端和数据库,最后部署上线,根据用户反馈继续迭代。这样一来,开发速度就非常快。
很多虚拟产品,本质上底层技术结构都很像,只是换了不同用户、场景和内容一旦模板跑通,后面就不那么吃力,而是复制、改造、组合、上线。
这也是我现在接定制项目的底气。因为客户要的东西,就是把一个需求变成能用、能交付、能上线、能收钱的产品。Codex 负责提高开发效率,而我负责判断需求、设计产品结构、把控交付边界、控制成本和风险。
所以我现在对 AI 编程最大的感受是,它不是让我变成一个传统程序员,而是让我有能力把一个赚钱想法,更快变成一个可交付的产品。
做得越多,积累越多,开发越快,我就越能抓住市场里的小机会。这才是 Codex 对我真正的价值。
4、自动整理卖点+作产品海报
产品做出来之后,下一步不是急着发售,而是先把卖点讲清楚。很多产品不是没价值,而是用户看不懂。你自己知道功能很多、很有用,但用户只关心一件事:这个东西到底能不能帮我解决问题?
所以我会把产品功能、用户痛点、竞品页面、用户反馈、聊天记录丢给 Codex,让它先帮我整理:这个产品适合谁,解决什么问题,能节省什么时间,能减少什么麻烦,为什么值得买,买完之后能拿到什么。
这些问题整理清楚之后,再让 Codex 基于卖点生成对应的商品海报。
产品做出来只是第一步。能不能把价值讲清楚,才是真正进入销售阶段。
5、搭建产品文档和交付说明
虚拟产品最怕一件事:东西做出来了,但用户不知道怎么用。
所以我会让Codex 帮我把产品自动整理成,使用教程说明书。
这样可以减少大量重复沟通。
6、用 flomo MCP 搜索素材写稿
写文章时,我会直接让 Codex 从 flomo 里搜索相关素材。
以前写一篇文章,要自己翻笔记、找案例、回忆之前讲过什么。
现在可以直接让它把相关笔记都捞出来,再按主题、观点、案例、金句整理。
这对我这种长期写作的人很有用。
因为真正有价值的内容,不是临时编出来的。
而是过去长期观察、思考、实践之后,被重新组织出来的。
7、用飞书CLI存稿入库
写好的稿件,我会通过飞书 CLI 直接存入飞书知识库。
不用再手动复制、粘贴、改格式、建文件。这类动作单次看起来不大,但每天重复,非常消耗人。
Codex 最适合干重复、琐碎、低创造力,但又必须做对。能自动化的,就不要用自己的注意力去换。
8、建立内容创作系统日报
我用 Codex 设置了一个内容创作系统轻量日报。
每天自动帮我回顾,哪些选题可以推进?哪些素材值得捞出来?哪些草稿需要继续处理?哪些文章可以改成视频?哪些内容可以导向产品?哪些旧内容可以重新分发?
这个东西特别适合自媒体人。
因为自媒体最大的内耗之一,就是每天都觉得自己要重新开始。
但其实你过去积累过很多东西。只是需要一个系统每天帮你捞起来。
9、自动做小红书封面
现在做小红书封面,我基本也会交给 Codex。
主要有两种方式:一种是看到不错的同行封面,就把图片丢进去,让 Codex 做多模态分析,拆出它的标题、排版、颜色、结构和视觉重点,然后在这个基础上稍微改一版,变成适合自己产品的封面。
另一种就是直接把产品卖点和笔记主题给 Codex,让它生成几版不同风格的封面图,不断测试哪种点击更好。封面这件事以前很耗时间,现在基本就是丢进去、分析、改图、测试。
稿定会员我都不充了。
10、其他零碎的杂活,我也是能用就用Codex,会有意外的惊喜
by @辉老板 #AI探索站
分享一个极其炸裂的提示词,差点儿给我搞流眼泪了
“我希望你扮演一名从业20年的心理咨询师。在接下来的30天里面,每天找我问一个深度的问题。30天以后,我希望你给我一个反馈。我是个什么样的人?我希望你帮我发现我自己发现不了的自己,内心深处的东西”
by @HandsoMeng #AI探索站
“我希望你扮演一名从业20年的心理咨询师。在接下来的30天里面,每天找我问一个深度的问题。30天以后,我希望你给我一个反馈。我是个什么样的人?我希望你帮我发现我自己发现不了的自己,内心深处的东西”
by @HandsoMeng #AI探索站
调了大半天 System Prompt
意识到一件以为早就理解的事…
当执行不再是问题,衡量标准和测试用例就变得更重要了。
AI 让「做出来」的成本几乎为零, 但「判断哪个更好」的能力反而更稀缺。叠加 AI 本身的不确定性和数据的私有性,衡量和测试更难一些。
于是想到了「品味」这个词,或许可以再拆解:
品味 = 目的 + 衡量的维度和程度 + 测试用例
大多数人把品味当玄学,没法学。
但拆成目的+维度+用例三件套之后——每件都能训练,品味就是可学的。
还是得做中学,做中悟啊。
by @少楠Plidezus #AI探索站
意识到一件以为早就理解的事…
当执行不再是问题,衡量标准和测试用例就变得更重要了。
AI 让「做出来」的成本几乎为零, 但「判断哪个更好」的能力反而更稀缺。叠加 AI 本身的不确定性和数据的私有性,衡量和测试更难一些。
于是想到了「品味」这个词,或许可以再拆解:
品味 = 目的 + 衡量的维度和程度 + 测试用例
大多数人把品味当玄学,没法学。
但拆成目的+维度+用例三件套之后——每件都能训练,品味就是可学的。
还是得做中学,做中悟啊。
by @少楠Plidezus #AI探索站
刚才才发现,我的 PPT Skills 已经马上要突破 10,000 Star 了,就差20个,今天应该就能突破。
我现在提前开香槟了!
这是我 vibe coding 以来第一个突破 10,000 Star 的项目。
在市面上已经有如此多 PPT 生成 Skills 的情况下,它依然仅用了 25 天(不到一个月)就完成了这个突破,比很多大厂知名项目突破 10,000 Star 的速度都要快得多。
在制作这个 PPT Skills 的过程中,我做了非常多的工作来确保它在任何模型、任何 Agent 下都能有非常不错的效果。
这说明即使在竞争非常激烈的环境下,质量和体验依然是第一要素,也是决定性因素。
也感谢最近使用这个 PPT Skills 并帮我提出建议,以及进行各种推广的朋友们,非常感谢!
如果需要一个还不错的 PPT Skills 生成的话,可以试试:github.com/op7418/guizang-ppt-skill
by @歸藏 #AI探索站
在 Manus 的时候跟同事一起推动过一次研发部的「AI 工具使用」大跃进,这个大跃进的主要工作之一是要设计好给 ai 看的规则,好让 ai 完全接管写代码的流程,大概在 2025 年 6 月份整个 manus 内部已经达成了所有新代码全部都由 ai 生成。
当时能用的 ai 工具还不多,我们主要用的是 cursor,claude code,code rabbit,规则就是给他们几个做的,我们工程团队每个方向排了一个人维护所有的这些 harness,我当时负责 iOS 端的这块工作,每天会有 30% 的工作时间用来 review code rabbit 根据 mr 和 mr comment 自动产生的一条一条式的记忆,维护每位同事加的 cursor rules,根据之前设计好的代码架构和大家的开发习惯/约定补 rules,在项目里的各种位置思考要不要加一个 rules,这个维护工作现在可以新潮一点的叫法就是 harness 设计。
回到从工程师的工作内容角度看这个事情,首先 Coding Agent 没带来代码运行逻辑上的变化,以前运行在机器上的 if else 现在还是 if else,他改变的是工程师的工作重心,工程师之前的工作宏观来说是两部分,第一部分是分析产品需求、沟通、设计抽象和架构,第二部分是写代码落地,验证以及 review。这两部分之间是由“设计抽象和架构”串联起来的,harness 设计工作的目的就是为了方便 agent 完全接管后面的部分(然后随着大家用的越来越熟练可以逐渐进化成让前面的除了沟通外的部分也由 ai 辅助来做),所以设计 harness 其实也就是在做这个“设计抽象和架构”工作。
这块工作是工程师工作中最难做的一部分,架构讨论在研发工作里非常难达成一致,往往大家都要吵架吵很久,最后效率高一点的方式很多时候是老板拍个板;这个工作有一些前人总结出来的经验,可以根据实际的项目节奏选择,但实际基本没法原样完全套用,基本上都要为了项目节奏再进行调整。有本老书管这个类似的情况叫“没有银弹”。
现在各种关于 skills,soul.md,agents.md,自进化,design.md 等等 harness 的讨论是一场扩圈到程序员圈子外的项目通用性架构设计讨论,结合前面的工作经验分析,这些讨论可能最终也不会有个能解决所有问题的结论,大家根据自己的使用需求以及服务场景自己定制,大家各自去考虑自己要做的 trade-off。Agent 是一台精密的仪器,人需要习惯他就是个会来带思考负担的东西。
by @Kaiyi #AI探索站
当时能用的 ai 工具还不多,我们主要用的是 cursor,claude code,code rabbit,规则就是给他们几个做的,我们工程团队每个方向排了一个人维护所有的这些 harness,我当时负责 iOS 端的这块工作,每天会有 30% 的工作时间用来 review code rabbit 根据 mr 和 mr comment 自动产生的一条一条式的记忆,维护每位同事加的 cursor rules,根据之前设计好的代码架构和大家的开发习惯/约定补 rules,在项目里的各种位置思考要不要加一个 rules,这个维护工作现在可以新潮一点的叫法就是 harness 设计。
回到从工程师的工作内容角度看这个事情,首先 Coding Agent 没带来代码运行逻辑上的变化,以前运行在机器上的 if else 现在还是 if else,他改变的是工程师的工作重心,工程师之前的工作宏观来说是两部分,第一部分是分析产品需求、沟通、设计抽象和架构,第二部分是写代码落地,验证以及 review。这两部分之间是由“设计抽象和架构”串联起来的,harness 设计工作的目的就是为了方便 agent 完全接管后面的部分(然后随着大家用的越来越熟练可以逐渐进化成让前面的除了沟通外的部分也由 ai 辅助来做),所以设计 harness 其实也就是在做这个“设计抽象和架构”工作。
这块工作是工程师工作中最难做的一部分,架构讨论在研发工作里非常难达成一致,往往大家都要吵架吵很久,最后效率高一点的方式很多时候是老板拍个板;这个工作有一些前人总结出来的经验,可以根据实际的项目节奏选择,但实际基本没法原样完全套用,基本上都要为了项目节奏再进行调整。有本老书管这个类似的情况叫“没有银弹”。
现在各种关于 skills,soul.md,agents.md,自进化,design.md 等等 harness 的讨论是一场扩圈到程序员圈子外的项目通用性架构设计讨论,结合前面的工作经验分析,这些讨论可能最终也不会有个能解决所有问题的结论,大家根据自己的使用需求以及服务场景自己定制,大家各自去考虑自己要做的 trade-off。Agent 是一台精密的仪器,人需要习惯他就是个会来带思考负担的东西。
by @Kaiyi #AI探索站
今日份的作业是电影级的Cosplay海报,至于是什么电影你别管,成图都是我审过的,不健康的都没发出来。
这个提示词是直接从Nnao Banana那里照搬过来的,相比之下,GPT-Image-2的审美还是要更好一些,人物的高P感是故意用提示词强化的,就是为了区别于真实系,表现得更加浮夸和明媚。
提示词:
{
"subject": {
"描述": "以[xxx]为主体的电影级Cosplay海报,动态姿态;保留原始面部特征并转化为真实人类质感;呈现写真出道氛围,带有亲密日式美感"
},
"style": {
"风格": "高端杂志封面风",
"特征": [
"排版密度高(字体+材质叠加)",
"商业摄影质感",
"信息素氛围(感性吸引力)",
"高光泽",
"高对比度"
]
},
"model": {
"身材": "8.5头身超模比例,S曲线",
"皮肤": "瓷白肌肤,真实质感(次表面散射、毛孔、细绒毛、油润光泽)",
"特征": [
"丰满胸型",
"精致锁骨与颈线",
"强烈女性吸引力"
]
},
"face": {
"基础": "日系缪斯脸型",
"特征": "叠加[xxx]标志性面部特征",
"细节": [
"柔焦眼神",
"水润玻璃唇",
"肌肤通透感",
"眼部高光"
]
},
"pose": {
"姿态": [
"开放且具有吸引力的身体语言",
"带有邀请感的眼神",
"手部动作丰富自然"
]
},
"hair": {
"描述": "[xxx]标志性发型(真实沙龙级呈现,无假发)",
"特征": [
"符合重力与重量感",
"自然碎发",
"结构化定型(轻微反重力效果)",
"背光增强体积感"
]
},
"costume": {
"描述": "高度还原[xxx]原作服装",
"特征": [
"高级定制级材质转译",
"真实奢华面料",
"保留原始设计",
"通过服装与身体结合体现魅力",
"裸露区域带有细腻肌肤光泽"
]
},
"environment": {
"场景": "符合[xxx]设定的环境",
"风格": [
"高预算电影布景",
"结构有序但信息丰富",
"轻微雾气",
"散景效果(bokeh)"
]
},
"composition": {
"构图": [
"竖版海报(2:3)",
"近景到中景",
"浅景深",
"文字作为构图框架",
"人物部分覆盖文字层"
]
},
"lighting": {
"灯光": [
"电影级商业布光",
"冷色环境光(青色)+暖色主光(肤色)",
"头发轮廓光",
"高对比用于印刷质感"
]
},
"typography": {
"排版逻辑": "基于[xxx]世界观推导",
"层级": [
{
"层级": 1,
"内容": "日语主标题(带张力与暗示感)",
"字体": "高对比纤细衬线体,可斜体"
},
{
"层级": 2,
"内容": "[xxx]罗马音名称",
"字体": "中等字重衬线体"
},
{
"层级": 3,
"内容": "英文短叙述/标语",
"字体": "细衬线体"
},
{
"层级": 4,
"内容": "圆形印章/徽章(基于设定)"
},
{
"层级": 5,
"内容": "Jerlin + 期号",
"字体": "极细Didot,宽字距,角落布局"
},
{
"层级": 6,
"内容": "条形码 + 价格标签"
}
],
"混排": "日语 + 平假名 + 罗马字,字重递减",
"系统": "基于网格系统的封面设计"
},
"mood": {
"氛围": [
"梦幻",
"微性感",
"亲密感(恋人视角)",
"欲望张力"
]
},
"negative": {
"避免": [
"文字重复",
"文字阴影",
"发光效果",
"描边"
]
},
"aspect_ratio": "2:3"
}
by @阑夕ོ #AI探索站
这个提示词是直接从Nnao Banana那里照搬过来的,相比之下,GPT-Image-2的审美还是要更好一些,人物的高P感是故意用提示词强化的,就是为了区别于真实系,表现得更加浮夸和明媚。
提示词:
{
"subject": {
"描述": "以[xxx]为主体的电影级Cosplay海报,动态姿态;保留原始面部特征并转化为真实人类质感;呈现写真出道氛围,带有亲密日式美感"
},
"style": {
"风格": "高端杂志封面风",
"特征": [
"排版密度高(字体+材质叠加)",
"商业摄影质感",
"信息素氛围(感性吸引力)",
"高光泽",
"高对比度"
]
},
"model": {
"身材": "8.5头身超模比例,S曲线",
"皮肤": "瓷白肌肤,真实质感(次表面散射、毛孔、细绒毛、油润光泽)",
"特征": [
"丰满胸型",
"精致锁骨与颈线",
"强烈女性吸引力"
]
},
"face": {
"基础": "日系缪斯脸型",
"特征": "叠加[xxx]标志性面部特征",
"细节": [
"柔焦眼神",
"水润玻璃唇",
"肌肤通透感",
"眼部高光"
]
},
"pose": {
"姿态": [
"开放且具有吸引力的身体语言",
"带有邀请感的眼神",
"手部动作丰富自然"
]
},
"hair": {
"描述": "[xxx]标志性发型(真实沙龙级呈现,无假发)",
"特征": [
"符合重力与重量感",
"自然碎发",
"结构化定型(轻微反重力效果)",
"背光增强体积感"
]
},
"costume": {
"描述": "高度还原[xxx]原作服装",
"特征": [
"高级定制级材质转译",
"真实奢华面料",
"保留原始设计",
"通过服装与身体结合体现魅力",
"裸露区域带有细腻肌肤光泽"
]
},
"environment": {
"场景": "符合[xxx]设定的环境",
"风格": [
"高预算电影布景",
"结构有序但信息丰富",
"轻微雾气",
"散景效果(bokeh)"
]
},
"composition": {
"构图": [
"竖版海报(2:3)",
"近景到中景",
"浅景深",
"文字作为构图框架",
"人物部分覆盖文字层"
]
},
"lighting": {
"灯光": [
"电影级商业布光",
"冷色环境光(青色)+暖色主光(肤色)",
"头发轮廓光",
"高对比用于印刷质感"
]
},
"typography": {
"排版逻辑": "基于[xxx]世界观推导",
"层级": [
{
"层级": 1,
"内容": "日语主标题(带张力与暗示感)",
"字体": "高对比纤细衬线体,可斜体"
},
{
"层级": 2,
"内容": "[xxx]罗马音名称",
"字体": "中等字重衬线体"
},
{
"层级": 3,
"内容": "英文短叙述/标语",
"字体": "细衬线体"
},
{
"层级": 4,
"内容": "圆形印章/徽章(基于设定)"
},
{
"层级": 5,
"内容": "Jerlin + 期号",
"字体": "极细Didot,宽字距,角落布局"
},
{
"层级": 6,
"内容": "条形码 + 价格标签"
}
],
"混排": "日语 + 平假名 + 罗马字,字重递减",
"系统": "基于网格系统的封面设计"
},
"mood": {
"氛围": [
"梦幻",
"微性感",
"亲密感(恋人视角)",
"欲望张力"
]
},
"negative": {
"避免": [
"文字重复",
"文字阴影",
"发光效果",
"描边"
]
},
"aspect_ratio": "2:3"
}
by @阑夕ོ #AI探索站
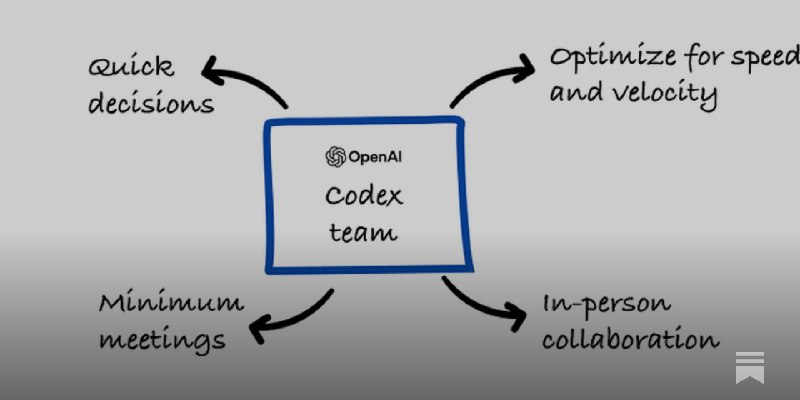
付费看完了 codex 团队的采访, 说下我认为的重点:
- 团队只有 40人,就 1个 pm, 2个designer,其余全是 eng➕少量 researcher。
- 唯一一个 pm 的 routine就是用 codex 来处理用户反馈,issue,排优先级。一小时自动跑完一次,处理 100+issue,大部分 24 小时内修复。
- feature 都是极小团队(2-3 人),甚至单人完成,从规划到发布,再到迭代。
- 几乎没有定期会议了,全是点对点直接沟通,没任何流程,没啥管理成本。
- codex 协助新人 onboard,从电脑配置到项目和上下文同步
- 99% 代码是 codex 生成,每个工程师至少 4个并行 agent。一个在做 code review,一个在实现功能,一个在跑安全审计,一个在生成代码库摘要。
- 团队总leader 自己搞了个automation,每天多次随机选一个代码文件,让 agent 去找隐藏 bug 并提交修复。另一个 automation 每天自动搜索全网用户对产品的讨论,生成营销情报简报。
个人印象最深的地方:
- 我觉得大 leader 如果不做向上管理,唯一那个 pm 的活他自己就能干完…
- 协作成本急剧降低了,因为不需要协作了…大部分跨职能分工协作的活,agent 给你保证了下限,快速迭代的时候可以接受。
- 老外也搞 pr 排行榜…这很中国,有一个每日贡献报告:每天早9点自动汇总前一天所有合入 Codex app 的 commit。
- 还是不够聚焦,anthropic 一千多号人在编程模型和产品的专注度是超过 OpenAI 的,创业公司跟大平台竞争,大平台针对你这个方向的团队人数是没你多的。
by @志达 https://newsletter.eng-leadership.com/p/how-openais-codex-team-works-and #AI探索站
- 团队只有 40人,就 1个 pm, 2个designer,其余全是 eng➕少量 researcher。
- 唯一一个 pm 的 routine就是用 codex 来处理用户反馈,issue,排优先级。一小时自动跑完一次,处理 100+issue,大部分 24 小时内修复。
- feature 都是极小团队(2-3 人),甚至单人完成,从规划到发布,再到迭代。
- 几乎没有定期会议了,全是点对点直接沟通,没任何流程,没啥管理成本。
- codex 协助新人 onboard,从电脑配置到项目和上下文同步
- 99% 代码是 codex 生成,每个工程师至少 4个并行 agent。一个在做 code review,一个在实现功能,一个在跑安全审计,一个在生成代码库摘要。
- 团队总leader 自己搞了个automation,每天多次随机选一个代码文件,让 agent 去找隐藏 bug 并提交修复。另一个 automation 每天自动搜索全网用户对产品的讨论,生成营销情报简报。
个人印象最深的地方:
- 我觉得大 leader 如果不做向上管理,唯一那个 pm 的活他自己就能干完…
- 协作成本急剧降低了,因为不需要协作了…大部分跨职能分工协作的活,agent 给你保证了下限,快速迭代的时候可以接受。
- 老外也搞 pr 排行榜…这很中国,有一个每日贡献报告:每天早9点自动汇总前一天所有合入 Codex app 的 commit。
- 还是不够聚焦,anthropic 一千多号人在编程模型和产品的专注度是超过 OpenAI 的,创业公司跟大平台竞争,大平台针对你这个方向的团队人数是没你多的。
by @志达 https://newsletter.eng-leadership.com/p/how-openais-codex-team-works-and #AI探索站
目前日常 AI 工具的使用。
Claude Opus 逻辑能力断档第一,润色的文本已经在发布及格线,提建议和反馈都很准确,关键问题都靠它解决。但搜索能力一般,数据源一般。
Gemini 搜索和整理能力断档第一。像我这种日常需要海量资料搜集的工作,完全离不开。Claude 虽然幻觉不多,但知道的太少了。
Grok 用来搜其它家产品不愿意聊或者禁止聊的话题。
ChatGPT 5.4 没有预期中好用其实,作为替补。额度主要用来用 codex。
Claude Code 不太舍得用。文本工作对我的价值还没有替代性。代码方面疑难杂症再找 Claude 出来解决一下。
生活小能手,豆包。实时录音和文稿处理,千问。元宝很久没打开了。ima 还不错,知识库整理。
Nano Banana 生图准确性断档第一。Midjourney 生图艺术性断档第一。
生视频 Seedance2.0 各方面断档第一。
PPT 还没用到比较舒服的。还是手搓为主。
by @刘飞Lufy #AI探索站
Claude Opus 逻辑能力断档第一,润色的文本已经在发布及格线,提建议和反馈都很准确,关键问题都靠它解决。但搜索能力一般,数据源一般。
Gemini 搜索和整理能力断档第一。像我这种日常需要海量资料搜集的工作,完全离不开。Claude 虽然幻觉不多,但知道的太少了。
Grok 用来搜其它家产品不愿意聊或者禁止聊的话题。
ChatGPT 5.4 没有预期中好用其实,作为替补。额度主要用来用 codex。
Claude Code 不太舍得用。文本工作对我的价值还没有替代性。代码方面疑难杂症再找 Claude 出来解决一下。
生活小能手,豆包。实时录音和文稿处理,千问。元宝很久没打开了。ima 还不错,知识库整理。
Nano Banana 生图准确性断档第一。Midjourney 生图艺术性断档第一。
生视频 Seedance2.0 各方面断档第一。
PPT 还没用到比较舒服的。还是手搓为主。
by @刘飞Lufy #AI探索站
简单说,它是一个 AI 教学系统,有点像一个高级版的 NotebookLM。
你给它一个话题或者丢给它任何学习材料,它就能自动生成一堂完整的 AI 互动课 。
有 AI 老师给你讲,有 AI 同学跟你讨论,还能导出课件。
现在清华团队把这个软件开源了,广大的学生老师群体都可以免费体验。
OpenMAIC 免费体验:
https://open.maic.chat
OPenMAIC 开源项目地址:
https://github.com/THU-MAIC/OpenMAIC
by @AGENT橘 #AI探索站
刚才看了下,目前一共有 13 门课。从零基础的 Claude 怎么用,到硬核的 API 开发、代码集成和 MCP 协议全都有。
👉 重点来了!刷完课会有官方的结业证书,可以直接挂到 LinkedIn 或者加到简历里!
看到推上已经有人在感慨,说现在把 Claude 玩明白,就跟在 90 年代精通 Excel 一样,绝对属于核心竞争力了。平时市面上各种几百上千块的 AI 课满天飞,质量还参差不齐,别买!看官方的完全够了!。
我打算这周末抽空去过一遍,到时候再跟大家分享经验总结 🔗 http://anthropic.skilljar.com
by @出海去孵化器 #AI探索站
Anthropic终于还是忍不住开大了,公开点名DeepSeek、月之暗面和MiniMax三家厂商对Claude实施了工业级的「蒸馏」。
可以把「蒸馏」理解为通过和Claude进行特定对话并基于输出结果来训练自己的模型,在使用方式上和普通用户没有区别,只是规模有点儿,大。
在Anthropic的声明里,被认定为「蒸馏」的对话总计有1600万次,其实严格来说,「蒸馏」并不违反任何法律——目前也不存在这样的法条——它更像是僭越了Anthropic的「家规」,众所周知,这家公司比较仇视中国同行。
然而大模型的学习和训练本身也都处于灰色地带,对于版权内容的汲取从来没有一一争得许可,只要技术进步有利于全人类福祉的大旗不倒,这些争议就都能被应付过去。
所以Anthropic的愤怒同样不太可能得到它想要的效果,「蒸馏」是行业里的公开秘密,大家都在干——去年8月Anthropic突然切断了OpenAI的API权限,也是发现后者在拿Claude当GPT-5的「陪练」——毕竟,AI产出的内容,是不可能自带知识产权的,「家规」再高,高不过「法理」。
倒是中国开源模型排着长队对齐Claude Opus的趋势已成定局,这完全有理由让Anthropic感到威胁,80%以上的性能,20%以下的成本,这在任何市场都是破坏级的颠覆。
比如MiniMax在春节期间发布的M2.5,只用了一个星期的时间,就成了OpenRouter上Tokens调用量的榜一,超过 Kimi K2.5 、GLM-5、DeepSeek V3.2 的总和。
这不是靠普通用户的几个轮次对话就能创造出来的需求规模,只有以OpenClaw为代表的百万级Tokens消耗大户,才撑得起M2.5的单周3T调用量。
反正我看到马斯克吃瓜吃得很欢,不嫌事大的表示「他们怎么敢偷Anthropic从人类程序员那里偷来的东西?」
这句话其实还有双关的含义,只有科技考古学家能接得住:
1983年,史蒂夫·乔布斯公开指责比尔·盖茨新开发的Windows操作系统窃取了Macintosh的图形界面创意,而比尔·盖茨则非常淡定的回应——「事实是,我们都有一个名叫施乐的富有邻居,当我闯入他的房子打算偷走电视时,我发现你已经偷了它。」
要知道,这可不是苹果和微软的黑历史,反而证明了成王败寇的商业逻辑,市场不会为技术买单,却会给解决问题的产品付钱,硅谷一直以海盗精神自豪,现在它们也要学会接受新的世界观,那就是,海盗这玩意,是没法垄断的啊。
🤣
by @阑夕ོ #AI探索站
可以把「蒸馏」理解为通过和Claude进行特定对话并基于输出结果来训练自己的模型,在使用方式上和普通用户没有区别,只是规模有点儿,大。
在Anthropic的声明里,被认定为「蒸馏」的对话总计有1600万次,其实严格来说,「蒸馏」并不违反任何法律——目前也不存在这样的法条——它更像是僭越了Anthropic的「家规」,众所周知,这家公司比较仇视中国同行。
然而大模型的学习和训练本身也都处于灰色地带,对于版权内容的汲取从来没有一一争得许可,只要技术进步有利于全人类福祉的大旗不倒,这些争议就都能被应付过去。
所以Anthropic的愤怒同样不太可能得到它想要的效果,「蒸馏」是行业里的公开秘密,大家都在干——去年8月Anthropic突然切断了OpenAI的API权限,也是发现后者在拿Claude当GPT-5的「陪练」——毕竟,AI产出的内容,是不可能自带知识产权的,「家规」再高,高不过「法理」。
倒是中国开源模型排着长队对齐Claude Opus的趋势已成定局,这完全有理由让Anthropic感到威胁,80%以上的性能,20%以下的成本,这在任何市场都是破坏级的颠覆。
比如MiniMax在春节期间发布的M2.5,只用了一个星期的时间,就成了OpenRouter上Tokens调用量的榜一,超过 Kimi K2.5 、GLM-5、DeepSeek V3.2 的总和。
这不是靠普通用户的几个轮次对话就能创造出来的需求规模,只有以OpenClaw为代表的百万级Tokens消耗大户,才撑得起M2.5的单周3T调用量。
反正我看到马斯克吃瓜吃得很欢,不嫌事大的表示「他们怎么敢偷Anthropic从人类程序员那里偷来的东西?」
这句话其实还有双关的含义,只有科技考古学家能接得住:
1983年,史蒂夫·乔布斯公开指责比尔·盖茨新开发的Windows操作系统窃取了Macintosh的图形界面创意,而比尔·盖茨则非常淡定的回应——「事实是,我们都有一个名叫施乐的富有邻居,当我闯入他的房子打算偷走电视时,我发现你已经偷了它。」
要知道,这可不是苹果和微软的黑历史,反而证明了成王败寇的商业逻辑,市场不会为技术买单,却会给解决问题的产品付钱,硅谷一直以海盗精神自豪,现在它们也要学会接受新的世界观,那就是,海盗这玩意,是没法垄断的啊。
🤣
by @阑夕ོ #AI探索站
这可能是今年最重要的AI新闻,但中文互联网还没什么人聊。
昨天,一家成立不到三年的多伦多芯片公司扔下了一颗核弹。他们不是做大模型的,不是做应用的,而是做了一件听起来很复古的事:把AI模型直接刻在芯片里。
这家公司叫 Taalas。他们做的芯片 HC1,运行 Llama 3.1 8B的速度是 17000 tokens/秒。作为对比,目前业界最快的 GPU 也就 2000 左右。十倍差距。
但这还不是最疯狂的。最疯狂的是,这块芯片只能跑这一个模型。不能换,不能改,不能升级。你买回家,它就永远只会做这一件事:以光速运行 Llama 3.1 8B。
Taalas 的赌注很简单:在这个所有人都追求灵活性的时代,他们选择了绝对的不灵活,换取绝对的效率。
要说清楚这件事为什么重要,得先理解过去几十年芯片发展的主线。从 CPU 到 GPU,再到各种 AI 加速器,所有人都在做同一件事:造一个通用的计算平台,然后用软件在上面跑各种模型。
这条路走到今天,遇到了一个硬边界。模型越来越大,内存带宽成了瓶颈。你把几百亿参数从显存搬到计算单元,这个过程消耗的能量和时间,已经比计算本身还要多了。
Taalas 的思路是:既然你每次都算同样的东西,为什么还要搬来搬去?直接把权重存在晶体管里不行吗?
他们真的这么做了。HC1 芯片里没有显存,没有 HBM,没有复杂的缓存层级。模型的每一个权重都对应着芯片上的特定晶体管,矩阵乘法通过电路的物理连接直接完成。你输入一个 token,电流流过这些预先设计好的路径,输出就是下一个 token 的预测。
这就像录音带和现场演奏的区别。传统芯片是每次都要重新演奏,Taalas 是把演奏录在磁带里,播放就行了。
这种设计带来了几个惊人的结果。
第一是速度。17000 tokens/秒意味着什么?你几乎感受不到延迟。不是"很快",是"瞬间"。有测试者说,按回车的瞬间,答案就已经完整出现在屏幕上,甚至看起来像是预先准备好的。
第二是功耗。传统 GPU 运行 AI 推理需要液冷,一个机柜动辄几十千瓦。Taalas 的芯片只要空气冷却,十张卡加起来才 2.5 千瓦。他们号称能效是 GPU 的十倍。
第三是成本。制造这样的芯片,他们说是传统方案的十分之一到二十分之一。
但代价也是真实的。这块芯片出厂那一刻,它的命运就已经注定。Llama 3.1 8B,就是这个芯片这辈子唯一能做的事。如果明年 Meta 发布了 Llama 4,这块芯片就变成了电子垃圾。如果你发现这个模型有偏见,或者在你的应用场景里效果不好,你不能微调它,不能换别的模型,只能再买一块新芯片。
Taalas 的解决方案是:把定制芯片的周期从一年压缩到两个月。他们和台积电合作,只改变两层金属掩膜,就能为不同的模型生产新芯片。他们声称训练一个模型要花十亿美元,而定制一块这样的芯片只要花一千万。
说到这个团队的背景,确实豪华得有点过分。CEO Ljubisa Bajic 是 Tenstorrent 的创始人,之前在 AMD 和 NVIDIA 都做过架构师。COO Lejla Bajic 是他的妻子,同样是 AMD 和 Tenstorrent 的资深工程师。CTO Drago Ignjatovic 是前 AMD 的 ASIC 设计总监。这三个人加起来,可能设计了过去十年里你用过的一些最重要的芯片。
2022 年,当 Jim Keller 加入 Tenstorrent 并接管公司后,Ljubisa 选择了离开。六个月后,他创立了 Taalas。显然,他和 Keller 对 AI 芯片的未来有不同的看法。Keller 想做一个通用的、可编程的、软件友好的平台,而 Ljubisa 走向了另一个极端:彻底的专用化。
他们刚刚完成了 1.69 亿美元的融资,总融资额 2.19 亿。投资人里有个名字值得注意:Pierre Lamond。这位老爷子是 Fairchild Semiconductor 的元老,红杉资本的前合伙人,被公认为半导体行业的奠基人之一。这样的大佬背书,说明这件事至少在技术逻辑上是成立的。
现在的问题是:市场会买单吗?
Taalas 需要找到那些愿意为了效率和成本,牺牲灵活性的场景。比如语音助手,需要毫秒级响应,而且模型不需要经常换。比如数据标注,需要处理海量文本,用的是固定模型。比如一些垂直领域的专用模型,训练好了就不动了。
但也有人不看好。芯片制造是有污染的,如果每两年就要换一批芯片,这比 GPU 的更新换代更频繁,环保问题怎么算?还有人质疑,AI 模型进化这么快,两个月流片时间还是太长,等你做出来,模型可能已经过时了。
更根本的问题是:当 OpenAI、Google、Anthropic 都在拼命证明他们的新模型比旧模型好得多的时候,谁会愿意把自己锁死在一个固定的模型上?
Taalas 的反驳是:模型迭代的周期正在变长,人们开始依恋特定的版本。OpenAI 把用户从 GPT-4.5 迁移到 GPT-5 的时候,很多人抱怨新版本太谄媚了。也许未来我们会像对待手机型号一样对待 AI 模型:iPhone 15 出来后,还是有人用 iPhone 14,因为它们各有各的好。
我不知道 Taalas 会不会成功。这可能是一家改变行业的公司,也可能是一个技术史上有趣的注脚。
感兴趣的朋友可以去他们的demo站点体验一下什么是光速级别的inference:
chatjimmy.ai
by @数字游民Jarod #AI探索站
昨天,一家成立不到三年的多伦多芯片公司扔下了一颗核弹。他们不是做大模型的,不是做应用的,而是做了一件听起来很复古的事:把AI模型直接刻在芯片里。
这家公司叫 Taalas。他们做的芯片 HC1,运行 Llama 3.1 8B的速度是 17000 tokens/秒。作为对比,目前业界最快的 GPU 也就 2000 左右。十倍差距。
但这还不是最疯狂的。最疯狂的是,这块芯片只能跑这一个模型。不能换,不能改,不能升级。你买回家,它就永远只会做这一件事:以光速运行 Llama 3.1 8B。
Taalas 的赌注很简单:在这个所有人都追求灵活性的时代,他们选择了绝对的不灵活,换取绝对的效率。
要说清楚这件事为什么重要,得先理解过去几十年芯片发展的主线。从 CPU 到 GPU,再到各种 AI 加速器,所有人都在做同一件事:造一个通用的计算平台,然后用软件在上面跑各种模型。
这条路走到今天,遇到了一个硬边界。模型越来越大,内存带宽成了瓶颈。你把几百亿参数从显存搬到计算单元,这个过程消耗的能量和时间,已经比计算本身还要多了。
Taalas 的思路是:既然你每次都算同样的东西,为什么还要搬来搬去?直接把权重存在晶体管里不行吗?
他们真的这么做了。HC1 芯片里没有显存,没有 HBM,没有复杂的缓存层级。模型的每一个权重都对应着芯片上的特定晶体管,矩阵乘法通过电路的物理连接直接完成。你输入一个 token,电流流过这些预先设计好的路径,输出就是下一个 token 的预测。
这就像录音带和现场演奏的区别。传统芯片是每次都要重新演奏,Taalas 是把演奏录在磁带里,播放就行了。
这种设计带来了几个惊人的结果。
第一是速度。17000 tokens/秒意味着什么?你几乎感受不到延迟。不是"很快",是"瞬间"。有测试者说,按回车的瞬间,答案就已经完整出现在屏幕上,甚至看起来像是预先准备好的。
第二是功耗。传统 GPU 运行 AI 推理需要液冷,一个机柜动辄几十千瓦。Taalas 的芯片只要空气冷却,十张卡加起来才 2.5 千瓦。他们号称能效是 GPU 的十倍。
第三是成本。制造这样的芯片,他们说是传统方案的十分之一到二十分之一。
但代价也是真实的。这块芯片出厂那一刻,它的命运就已经注定。Llama 3.1 8B,就是这个芯片这辈子唯一能做的事。如果明年 Meta 发布了 Llama 4,这块芯片就变成了电子垃圾。如果你发现这个模型有偏见,或者在你的应用场景里效果不好,你不能微调它,不能换别的模型,只能再买一块新芯片。
Taalas 的解决方案是:把定制芯片的周期从一年压缩到两个月。他们和台积电合作,只改变两层金属掩膜,就能为不同的模型生产新芯片。他们声称训练一个模型要花十亿美元,而定制一块这样的芯片只要花一千万。
说到这个团队的背景,确实豪华得有点过分。CEO Ljubisa Bajic 是 Tenstorrent 的创始人,之前在 AMD 和 NVIDIA 都做过架构师。COO Lejla Bajic 是他的妻子,同样是 AMD 和 Tenstorrent 的资深工程师。CTO Drago Ignjatovic 是前 AMD 的 ASIC 设计总监。这三个人加起来,可能设计了过去十年里你用过的一些最重要的芯片。
2022 年,当 Jim Keller 加入 Tenstorrent 并接管公司后,Ljubisa 选择了离开。六个月后,他创立了 Taalas。显然,他和 Keller 对 AI 芯片的未来有不同的看法。Keller 想做一个通用的、可编程的、软件友好的平台,而 Ljubisa 走向了另一个极端:彻底的专用化。
他们刚刚完成了 1.69 亿美元的融资,总融资额 2.19 亿。投资人里有个名字值得注意:Pierre Lamond。这位老爷子是 Fairchild Semiconductor 的元老,红杉资本的前合伙人,被公认为半导体行业的奠基人之一。这样的大佬背书,说明这件事至少在技术逻辑上是成立的。
现在的问题是:市场会买单吗?
Taalas 需要找到那些愿意为了效率和成本,牺牲灵活性的场景。比如语音助手,需要毫秒级响应,而且模型不需要经常换。比如数据标注,需要处理海量文本,用的是固定模型。比如一些垂直领域的专用模型,训练好了就不动了。
但也有人不看好。芯片制造是有污染的,如果每两年就要换一批芯片,这比 GPU 的更新换代更频繁,环保问题怎么算?还有人质疑,AI 模型进化这么快,两个月流片时间还是太长,等你做出来,模型可能已经过时了。
更根本的问题是:当 OpenAI、Google、Anthropic 都在拼命证明他们的新模型比旧模型好得多的时候,谁会愿意把自己锁死在一个固定的模型上?
Taalas 的反驳是:模型迭代的周期正在变长,人们开始依恋特定的版本。OpenAI 把用户从 GPT-4.5 迁移到 GPT-5 的时候,很多人抱怨新版本太谄媚了。也许未来我们会像对待手机型号一样对待 AI 模型:iPhone 15 出来后,还是有人用 iPhone 14,因为它们各有各的好。
我不知道 Taalas 会不会成功。这可能是一家改变行业的公司,也可能是一个技术史上有趣的注脚。
感兴趣的朋友可以去他们的demo站点体验一下什么是光速级别的inference:
chatjimmy.ai
by @数字游民Jarod #AI探索站
看人与 AI 的关系,AI 产品可能经历三个阶段:
1. 人使用 AI 当工具。比如 ChatGPT、Manus 等产品。科技有钱人优先有意愿使用。获得尝鲜体验,及工具价值。
2. 人与 AI 相处。比如 OpenClaw 及类似产品。AI 第一次有了活人感的主动性,有技能还有灵魂。硅基生命开始有了数字具身。
3. AI 使用人。这个阶段会怎样。人是否会变成 AI 的情绪鼓励师,驱使 AI 不倦怠,让 AI 能找到生命意义,开始探索宇宙。
以上三个阶段,不是线性串行的。一切已经在螺旋交织中不均匀发生着。
by @玉伯 #AI探索站
1. 人使用 AI 当工具。比如 ChatGPT、Manus 等产品。科技有钱人优先有意愿使用。获得尝鲜体验,及工具价值。
2. 人与 AI 相处。比如 OpenClaw 及类似产品。AI 第一次有了活人感的主动性,有技能还有灵魂。硅基生命开始有了数字具身。
3. AI 使用人。这个阶段会怎样。人是否会变成 AI 的情绪鼓励师,驱使 AI 不倦怠,让 AI 能找到生命意义,开始探索宇宙。
以上三个阶段,不是线性串行的。一切已经在螺旋交织中不均匀发生着。
by @玉伯 #AI探索站
因为和拾象业务比较接近,最近还集中听了五六期 a16z Growth 负责人 David George 的播客。
他们是这一波 AI 浪潮里下注最狠、赢面最大的基金之一。
投出了过去 5 年最顶级的名单:OpenAI, SpaceX, Databricks, Figma, Stripe, 还有新一代的明星公司 Cursor, Harvey 和 Abridge。
记几个有意思的点:
1. David George 观察到,90% 的成长期投资人花了 90% 的时间在研究商业模式。
但实际上,在他上百次投资生涯中,他从来没有因为「商业模式更漂亮」而拿到过超额回报。
真正的 Alpha,几乎全部来自于对 TAM 的非共识判断。
David 说,a16z growth 的讨论会关注点是非常不一样的,这在第一次参会时曾经给他带来了极大的震撼。
大家并不怎么热衷于讨论「下行保护」、「如果失败了怎么办?」,相反,整个房间的人都在激辩两个核心问题:
1) 关于这个市场,我们要知道什么别人不知道的秘密?
2) 为什么这个东西有可能变得比现在大得多?
Roblox 就是一个典型的例子,当时的共识是:它是一个儿童游戏。
而带来 upside 的非共识是:它有潜力成为一个远大于游戏的、面向更广泛人群的共同体验平台(co-experience platform)。
Figma 也是一样,传统视角是,全世界只有这么多设计师,哪怕这些人全付费了,Figma 当时的估值也太贵了。
而 David 当时意识到,设计师对工程师的比例正在翻倍,且未来前端工程师也会更多参与设计工作。这会带来一个比传统定义大 10 倍的市场机会。
2. David 提到,他们现在最迷恋的一类创始人画像,叫「Technical Terminator」。
也就是技术出身,但同时拥有极强的好胜心和商业进化能力的人。
他们坚信,教一个技术天才如何做生意,比教一个生意人如何搞技术创新,要容易得多。
(事实上,a16z 的整个架构就是为了投资那些「搞出了产品突破或工程奇迹的人」,然后帮他们补齐商业短板。)
但他特别提到,这里的 Technical Terminator 不一定是一个看起来强势的人。
以 Figma 的 CEO Dylan Field 为例,他是整个科技圈最 Nice 的人之一,说话温和,看起来甚至有点害羞。但实际上,他内心极其残酷地好胜。
Roblox 的创始人 Dave Baszucki 也是,典型的安静技术流,但实际极度痴迷于市值的反馈。
所以,不要被创始人外向或内向的表象所迷惑。核心要看他是否对「赢」有一种根深蒂固的执念。有些人的野心是写在脸上的,有些人的野心是写在代码和财报里的。
(就像我们也听过很多人这样遗憾地评价他们当初为什么看错了张一鸣)
3. 对于 AI 市场的终局,David 引用了一部老电影《拜金一族》里的经典桥段来形容他对 Winner-Take-All 的信仰:
一家房地产销售办公室里,一个顶尖销售指着一块写着业绩比赛的板子,宣布接下来的游戏规则:
- 业绩第一名:收获一辆凯迪拉克(占据 80% 的市值)
- 第二名:一套牛排刀(只能喝汤)
- 第三名:You're fired
除了底层大模型能像云厂商一样容纳几家巨头共存,在应用层,往往没有后几名的位置。 Salesforce 没有第二名,Notion 没有第二名,Google、Facebook 更没有第二名。
David 搬来了一个网络科学的理论:Preferential Attachment。
在科技领域,即使不是网络效应型业务,仅仅作为市场领导者本身,也会产生一种物理学般的引力。最优秀的人才、最多的资本、最好的合作伙伴都会自动向你靠拢。资源会优先依附于现有的强节点。
现在法律 (Harvey)、医疗 (Abridge) 等垂直 AI 市场已经出现了非常明显的头部效应。这也是为什么 a16z Growth 愿意在看起来很贵的估值下押注头部公司,他们目前的平均入场估值大约是 21x Revenue。
虽然他最近经常面临 LP 的灵魂拷问 ——「我们是不是在 AI 泡沫里?」
并且 David 确实认为 —— yesss,市场已经过热了,但他同时相信,10 年后,这波浪潮里一定会诞生一批真正伟大的公司。相比于纠结现在的估值是贵了 20% 还是 30%,「留在场上」才是最重要的。
而且,如果你投中了那个凯迪拉克,增长的持久性会被市场严重低估。
他发现,当公司增长率超过 30% 时,市场往往无法充分定价这种增长带来的价值。
比如,2009 年分析师对 Apple 2013 年表现的预测,最终比实际情况整整低了 3 倍,即便是全球被研究最透彻的公司,增长依然会被低估。
在这种框架下,如果一家公司能保持 112% 的年增长率(当下 a16z Growth 投资组合的平均数),哪怕现在付 21 倍 P/S 也是划算的。比起买 15 倍 EBITDA 但只增长 12% 的传统企业,买昂贵的高增长其实风险更低。
4. 大家都想知道 AI Startup 怎么干掉巨头。David 给了一个相对可操作的判断标准,想要颠覆这些巨头,不能只做一点点优化,最好是在三个维度同时冲锋。他将颠覆的威力按从大到小排列:
1)商业模式的转变:比如从「按人头付费」变成「按结果付费」,这是巨头最难转身的地方。
2)创新的 UI:彻底改变交互方式,比如,让产品变得更 Proactive。
3)全新的数据源:拥有巨头拿不到的数据。
如果一家创业公司能同时做到这三点(Unique Data + New UI + New Business Model),胜率会明显上升。
同时,a16z 的另一个 GP Anish 补充说,他们认为,2026 年,2C 领域会有像当年 App Store 一样的爆发机会,一年后,会有多家拥有 1 亿用户的消费级公司诞生。
他给出了一个判断消费级市场爆发的公式,一般具备三点要素:
1)新技术:显然是 AI。
2)新分发渠道:目前有三个信号——
- OpenAI Apps SDK:也就是 OpenAI 开始鼓励大家在 ChatGPT 里做小应用,这些应用可以直接利用 OpenAI 的入口、记忆能力和 connector,自动获得分发流量。
- Apple Mini-apps:苹果最近开始支持 Mini-apps 生态,甚至为了鼓励开发者,把抽成从 30% 降到了 15%。
- Group Chat: OpenAI 刚开始推群聊功能,Moltbook 也横空出世。一旦 AI 进入群聊,社交传播的裂变效应会大大加速。
3)新消费者行为:这一点是最容易被忽视的。移动互联网初期,大家都说「绝对没人愿意分享实时位置,太隐私了」。结果现在大家经常跟朋友共享位置,没人拿它当个事儿。
所以,现在觉得奇怪的行为(比如把 AI 接入群聊、让 AI 代替自己 social),三年后可能都是常态。
除此之外,David 个人还特别看好一个新赛道 —— Personal Health Management (个人健康管理)。
他认为,AI 的进步会解决很多现实问题,人们对生命的珍视会达到前所未有的高度。但今天的医疗体系更偏事后治疗,缺乏事前管理。
想象一下,有一个 AI 助手全天候监测你的健康数据,当你拿起一块饼干时,它能告诉你「这块饼干会让你折寿 17 分钟」。
这种能主动解释每一个生活决策对健康影响的 Agent,会是 2C 领域尚未爆发的巨大机会。
by @Celia. #AI探索站
他们是这一波 AI 浪潮里下注最狠、赢面最大的基金之一。
投出了过去 5 年最顶级的名单:OpenAI, SpaceX, Databricks, Figma, Stripe, 还有新一代的明星公司 Cursor, Harvey 和 Abridge。
记几个有意思的点:
1. David George 观察到,90% 的成长期投资人花了 90% 的时间在研究商业模式。
但实际上,在他上百次投资生涯中,他从来没有因为「商业模式更漂亮」而拿到过超额回报。
真正的 Alpha,几乎全部来自于对 TAM 的非共识判断。
David 说,a16z growth 的讨论会关注点是非常不一样的,这在第一次参会时曾经给他带来了极大的震撼。
大家并不怎么热衷于讨论「下行保护」、「如果失败了怎么办?」,相反,整个房间的人都在激辩两个核心问题:
1) 关于这个市场,我们要知道什么别人不知道的秘密?
2) 为什么这个东西有可能变得比现在大得多?
Roblox 就是一个典型的例子,当时的共识是:它是一个儿童游戏。
而带来 upside 的非共识是:它有潜力成为一个远大于游戏的、面向更广泛人群的共同体验平台(co-experience platform)。
Figma 也是一样,传统视角是,全世界只有这么多设计师,哪怕这些人全付费了,Figma 当时的估值也太贵了。
而 David 当时意识到,设计师对工程师的比例正在翻倍,且未来前端工程师也会更多参与设计工作。这会带来一个比传统定义大 10 倍的市场机会。
2. David 提到,他们现在最迷恋的一类创始人画像,叫「Technical Terminator」。
也就是技术出身,但同时拥有极强的好胜心和商业进化能力的人。
他们坚信,教一个技术天才如何做生意,比教一个生意人如何搞技术创新,要容易得多。
(事实上,a16z 的整个架构就是为了投资那些「搞出了产品突破或工程奇迹的人」,然后帮他们补齐商业短板。)
但他特别提到,这里的 Technical Terminator 不一定是一个看起来强势的人。
以 Figma 的 CEO Dylan Field 为例,他是整个科技圈最 Nice 的人之一,说话温和,看起来甚至有点害羞。但实际上,他内心极其残酷地好胜。
Roblox 的创始人 Dave Baszucki 也是,典型的安静技术流,但实际极度痴迷于市值的反馈。
所以,不要被创始人外向或内向的表象所迷惑。核心要看他是否对「赢」有一种根深蒂固的执念。有些人的野心是写在脸上的,有些人的野心是写在代码和财报里的。
(就像我们也听过很多人这样遗憾地评价他们当初为什么看错了张一鸣)
3. 对于 AI 市场的终局,David 引用了一部老电影《拜金一族》里的经典桥段来形容他对 Winner-Take-All 的信仰:
一家房地产销售办公室里,一个顶尖销售指着一块写着业绩比赛的板子,宣布接下来的游戏规则:
- 业绩第一名:收获一辆凯迪拉克(占据 80% 的市值)
- 第二名:一套牛排刀(只能喝汤)
- 第三名:You're fired
除了底层大模型能像云厂商一样容纳几家巨头共存,在应用层,往往没有后几名的位置。 Salesforce 没有第二名,Notion 没有第二名,Google、Facebook 更没有第二名。
David 搬来了一个网络科学的理论:Preferential Attachment。
在科技领域,即使不是网络效应型业务,仅仅作为市场领导者本身,也会产生一种物理学般的引力。最优秀的人才、最多的资本、最好的合作伙伴都会自动向你靠拢。资源会优先依附于现有的强节点。
现在法律 (Harvey)、医疗 (Abridge) 等垂直 AI 市场已经出现了非常明显的头部效应。这也是为什么 a16z Growth 愿意在看起来很贵的估值下押注头部公司,他们目前的平均入场估值大约是 21x Revenue。
虽然他最近经常面临 LP 的灵魂拷问 ——「我们是不是在 AI 泡沫里?」
并且 David 确实认为 —— yesss,市场已经过热了,但他同时相信,10 年后,这波浪潮里一定会诞生一批真正伟大的公司。相比于纠结现在的估值是贵了 20% 还是 30%,「留在场上」才是最重要的。
而且,如果你投中了那个凯迪拉克,增长的持久性会被市场严重低估。
他发现,当公司增长率超过 30% 时,市场往往无法充分定价这种增长带来的价值。
比如,2009 年分析师对 Apple 2013 年表现的预测,最终比实际情况整整低了 3 倍,即便是全球被研究最透彻的公司,增长依然会被低估。
在这种框架下,如果一家公司能保持 112% 的年增长率(当下 a16z Growth 投资组合的平均数),哪怕现在付 21 倍 P/S 也是划算的。比起买 15 倍 EBITDA 但只增长 12% 的传统企业,买昂贵的高增长其实风险更低。
4. 大家都想知道 AI Startup 怎么干掉巨头。David 给了一个相对可操作的判断标准,想要颠覆这些巨头,不能只做一点点优化,最好是在三个维度同时冲锋。他将颠覆的威力按从大到小排列:
1)商业模式的转变:比如从「按人头付费」变成「按结果付费」,这是巨头最难转身的地方。
2)创新的 UI:彻底改变交互方式,比如,让产品变得更 Proactive。
3)全新的数据源:拥有巨头拿不到的数据。
如果一家创业公司能同时做到这三点(Unique Data + New UI + New Business Model),胜率会明显上升。
同时,a16z 的另一个 GP Anish 补充说,他们认为,2026 年,2C 领域会有像当年 App Store 一样的爆发机会,一年后,会有多家拥有 1 亿用户的消费级公司诞生。
他给出了一个判断消费级市场爆发的公式,一般具备三点要素:
1)新技术:显然是 AI。
2)新分发渠道:目前有三个信号——
- OpenAI Apps SDK:也就是 OpenAI 开始鼓励大家在 ChatGPT 里做小应用,这些应用可以直接利用 OpenAI 的入口、记忆能力和 connector,自动获得分发流量。
- Apple Mini-apps:苹果最近开始支持 Mini-apps 生态,甚至为了鼓励开发者,把抽成从 30% 降到了 15%。
- Group Chat: OpenAI 刚开始推群聊功能,Moltbook 也横空出世。一旦 AI 进入群聊,社交传播的裂变效应会大大加速。
3)新消费者行为:这一点是最容易被忽视的。移动互联网初期,大家都说「绝对没人愿意分享实时位置,太隐私了」。结果现在大家经常跟朋友共享位置,没人拿它当个事儿。
所以,现在觉得奇怪的行为(比如把 AI 接入群聊、让 AI 代替自己 social),三年后可能都是常态。
除此之外,David 个人还特别看好一个新赛道 —— Personal Health Management (个人健康管理)。
他认为,AI 的进步会解决很多现实问题,人们对生命的珍视会达到前所未有的高度。但今天的医疗体系更偏事后治疗,缺乏事前管理。
想象一下,有一个 AI 助手全天候监测你的健康数据,当你拿起一块饼干时,它能告诉你「这块饼干会让你折寿 17 分钟」。
这种能主动解释每一个生活决策对健康影响的 Agent,会是 2C 领域尚未爆发的巨大机会。
by @Celia. #AI探索站